原始链接:How CUDA Programming Works | NVIDIA On-Demand
本次演讲以安培架构的 A100 GPU 核心为例,讲解了 CUDA 编程的核心原理和优化点。
显存带宽限制
对于一个典型的 Ampere GPU,其理论上能够处理的数据数量相比最高端的 HBM2 内存带来的带宽还要多上 6 倍之多,虽然其中包含了数据复用和缓存等机制,但这一差距仍然不容小觑。

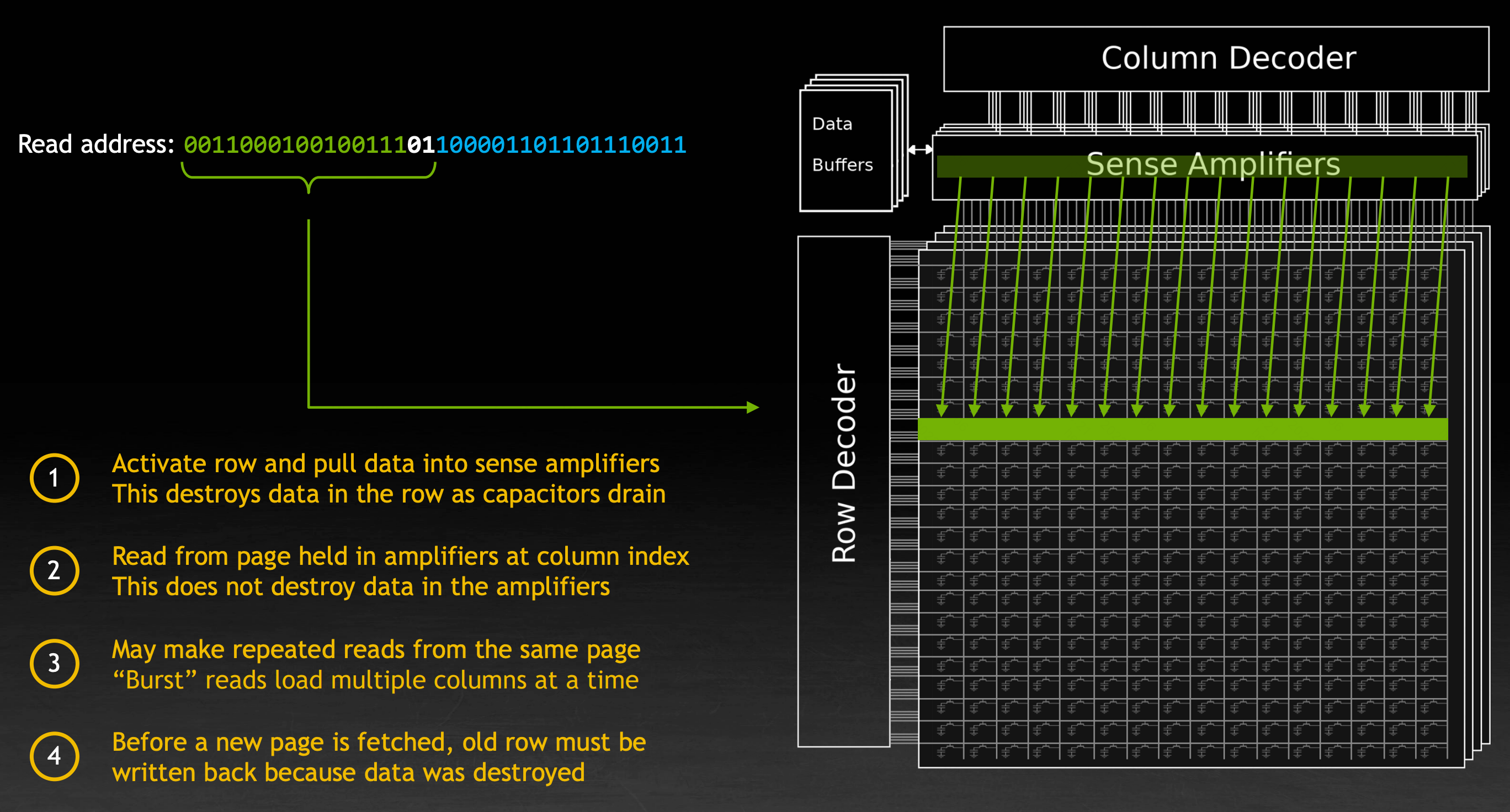
另一方面,在显存读取数据时的流程带来了特殊的读取性质。在显存中,地址按照高位和低位被分为行和列。在读取数据时的流程如下:
- 首先将数据从给定的行读取到感知增幅器(Sense Amplifier)中,这一操作会将行中原有的数据破坏
- 接着从增幅器中读取给定的列,这一操作不会破坏数据
- 如果接下来的请求来自同一行,可以重复地读取当前增幅器中的数据值,或者同时读取多列的数据
- 当需要选择新的一行时,增幅器中的数据需要被写回显存中
在这一过程中,跨行读取数据的耗时是在同行内读取数据的约三倍。为晶体管充电、放电的速度受限于物理的 RC 常数。
也就是说,当进行跨行数据读取时,实际的显存带宽比起理论值会小非常多。下图展示了在 A100 上以不同间隔每次读取8B数据的实际带宽:
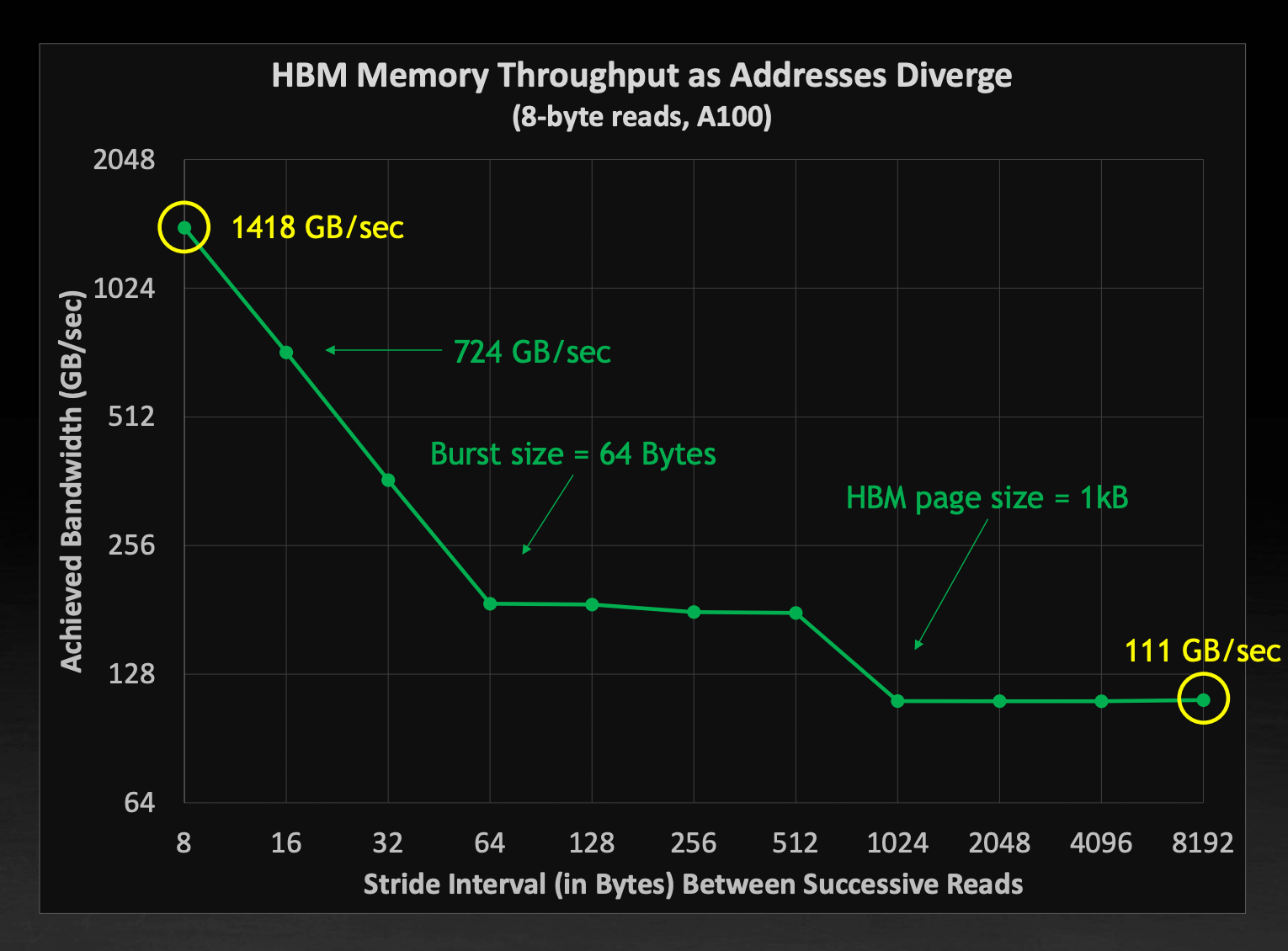
在紧凑读取时带宽最高,随后快速降低,在到达一次批量读取就能获得所有数据的阈值处稳定下来,接着在达到跨行读取时进一步降低。最低的带宽只有理论速度的约8%。
跨行读取的高延迟告诉我们需要尽量沿着数据排列的行主序方向进行读取。
计算资源限制
CUDA 的执行顺序
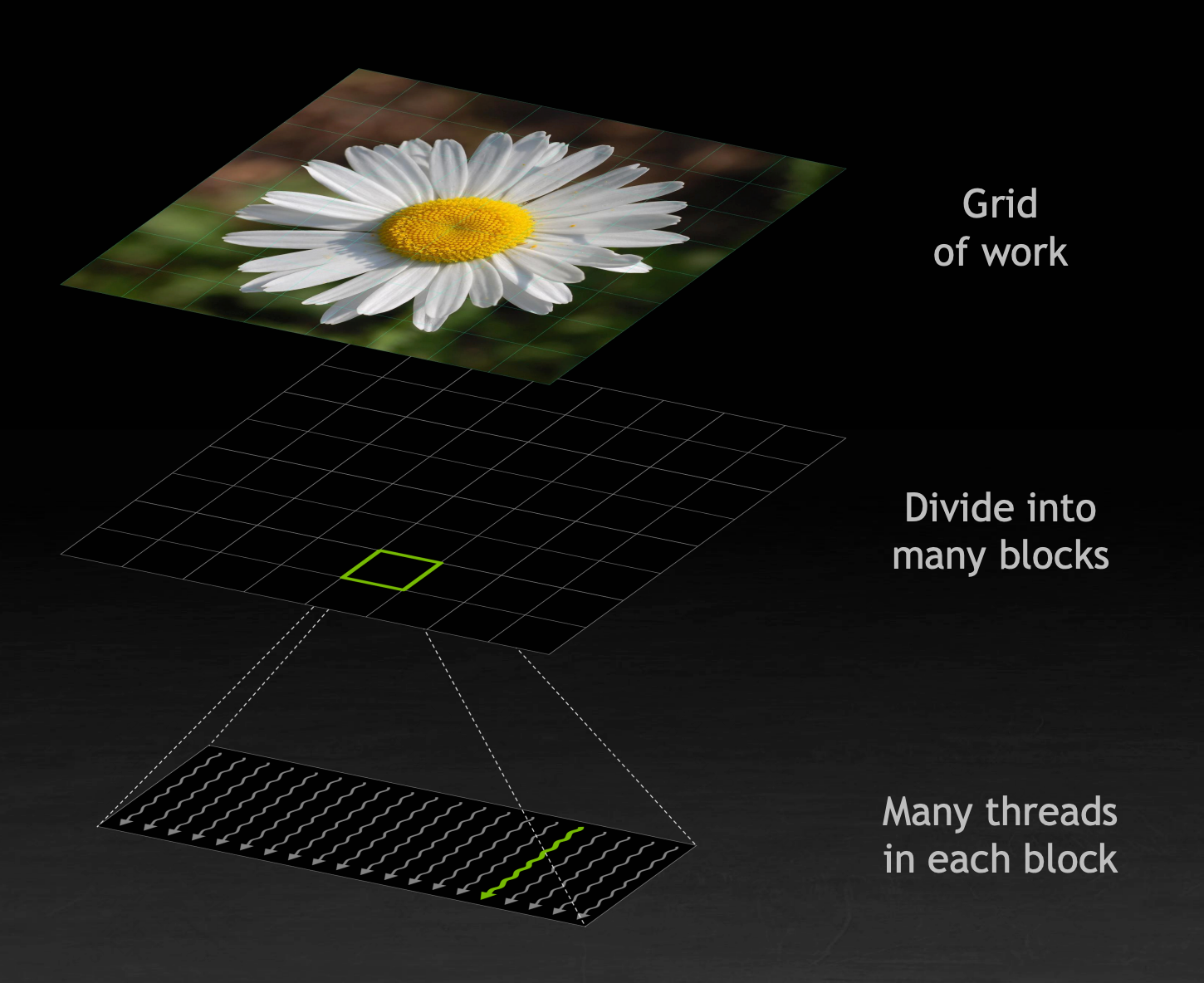
CUDA 使用 SIMT 执行框架,让统一指令在多个线程之上执行。
计算会被分分割为非常多的子任务,每个子任务会被 GPU 上的线程以固定数量为一组形成的 Thread Block 执行。每个 block 又可以被分为以 32 个线程为一组的 warp ,warp 是 GPU 的基础向量执行单元。
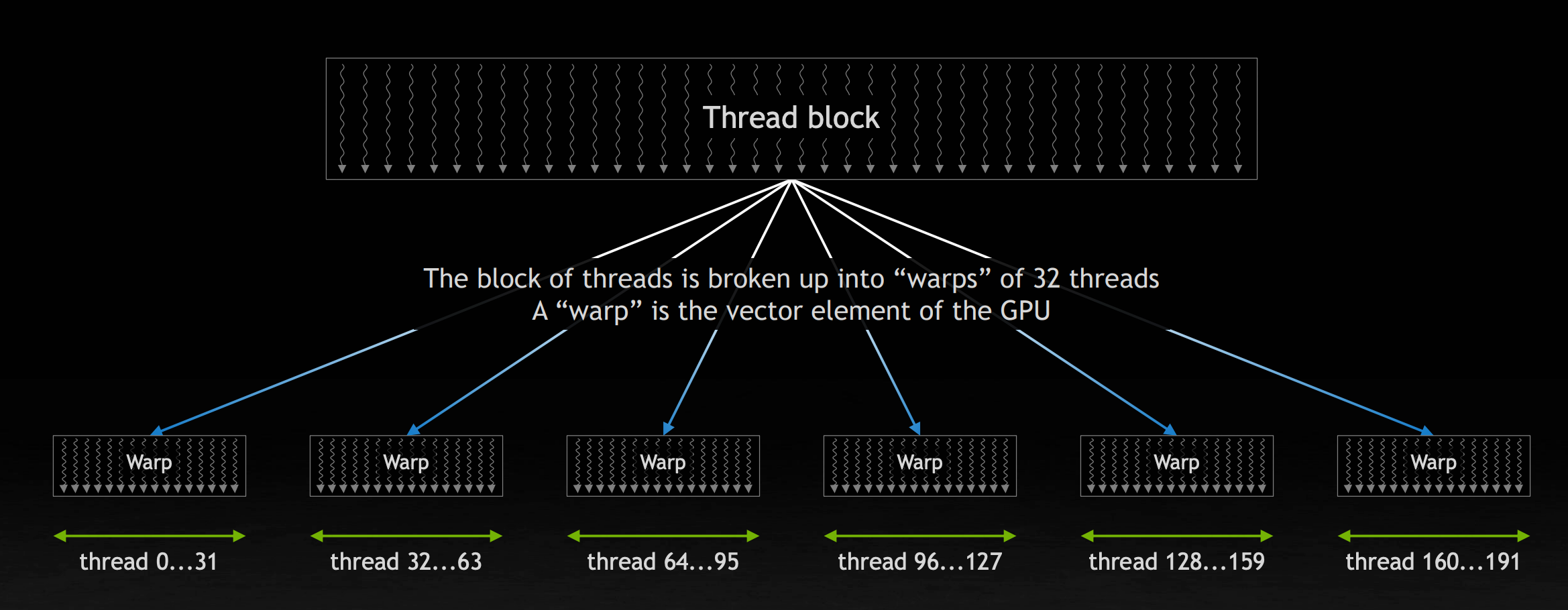
A100 的一个 SM 可以管理 64 个 warp ,它被分为 4 组不同的单元,各自拥有其对应的寄存器、指令缓存、分配器。由于 block 中的线程会共同读取数据,一个核心优化点在于让所有的线程按照线程 ID 访问相邻的内存,并尽可能地让线程数目满足读取的数据可以占满显存一行的倍数的大小。
GPU 的计算资源
一个 A100 GPU 的单个 SM 内的计算资源如图所示:
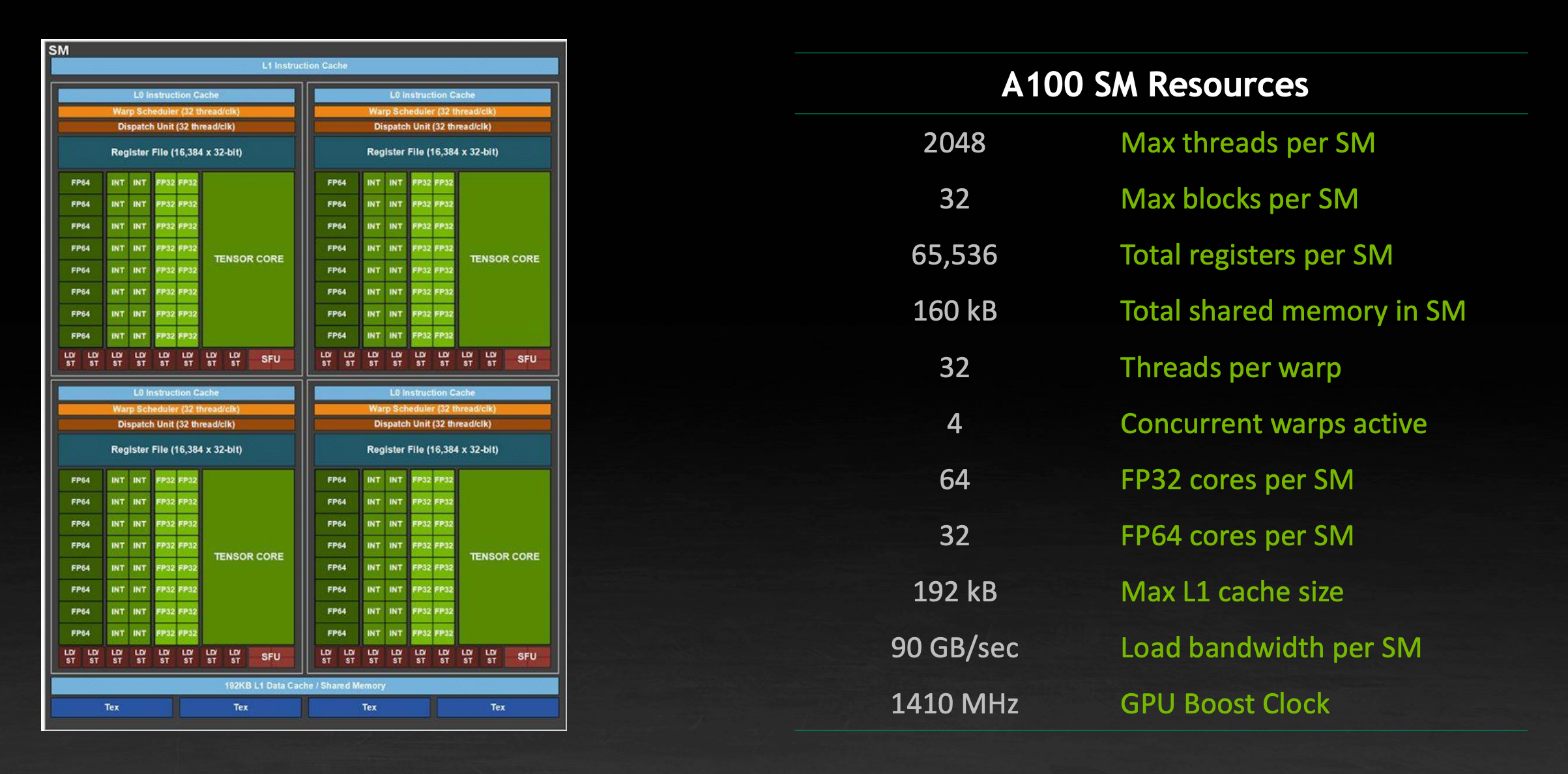
由于每个 SM 的显存带宽有限,GPU 会将工作优先分配到尽可能多的 SM 上。

为了实现计算速度的最大化,需要是的最大化并行的线程数量,但这一数量同时受限于共享内存的大小以及寄存器的大小。当共享内存或寄存器用尽时就无法申请新的 block 。另一个限制是单个 block 不能跨越多个 SM ,因为其中的线程需要通过共享内存等方法进行通信。
这里的优化点在于在设计算法时尽量优化其占用率(Occupancy),通过优化产生瓶颈的部分可以提高资源的利用率。
当一个 SM 被一类 block 充满但并非所有资源都被用尽时,它会尝试使用其他可并行的 block 填充剩余空间:

这些可并行的任务可以通过不同的 Stream 进行指定。
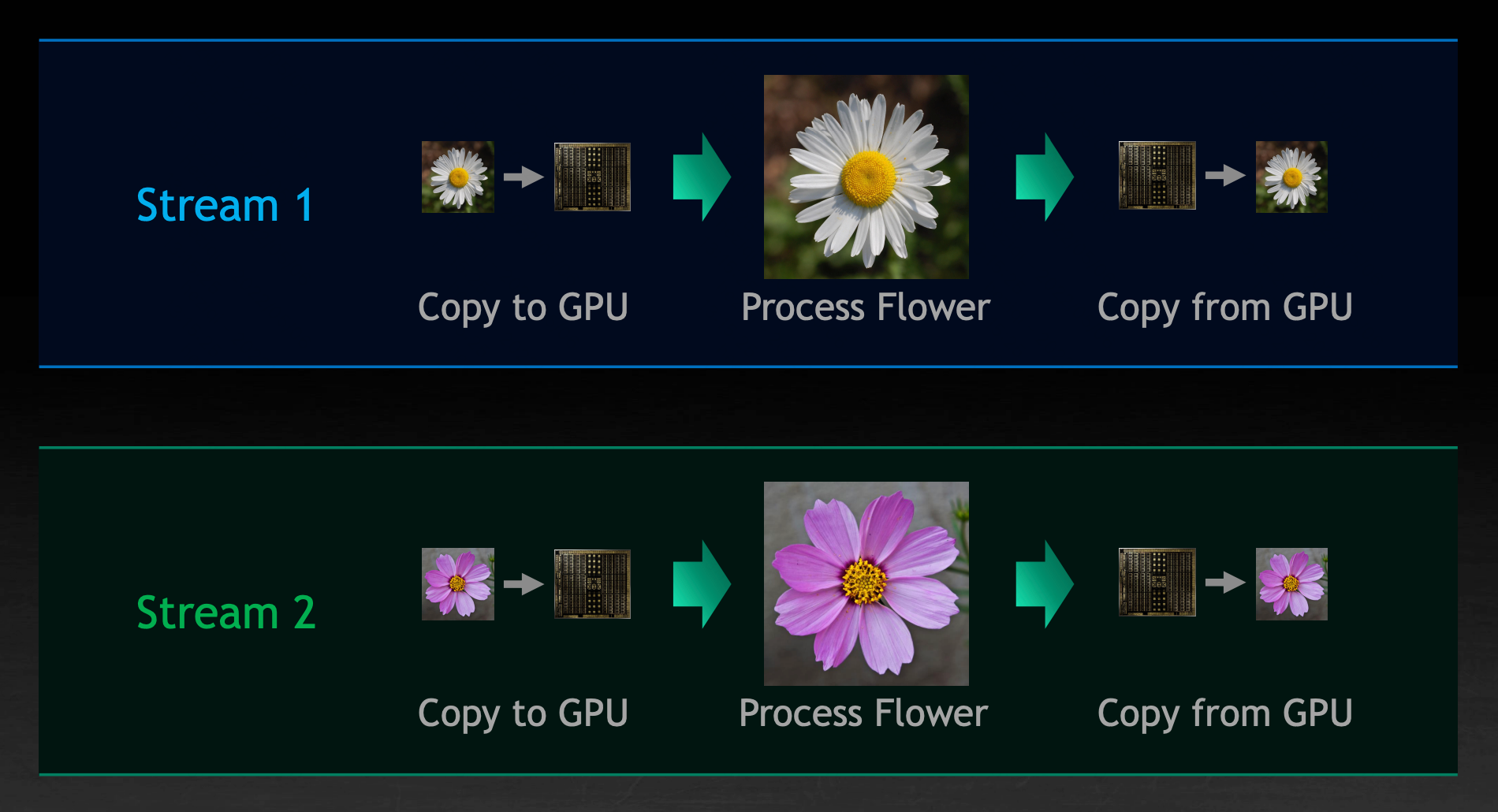
这里的优化点在于可以向 GPU 显示地指示互相独立的任务,以便 GPU 更好地并行它们,尽可能地填充可用资源。

